
Category: Expertise strategy
Are you familiar with Neo4j? According to emagine’s software developer Konrad Kaliciński, it’s one of the most prominent solutions in data management, widely used by organizations all over. In this article, Konrad takes us through the advantages, features, and practical applications of Neo4j.
Konrad Kaliciński, Wroclav, 13. July 2023
With the rapid growth of data, modern database solutions are gaining importance. Let’s start with what a graph is. According to Wikipedia:
“A graph is a fundamental object in graph theory, a mathematical structure used to represent and study relationships between objects.”
A graph database differs from relational or object-oriented databases in its structure. In a graph database, information is stored as nodes and relationships between them. This allows for more flexible and intuitive data modeling and exploration.
Unlike other types of databases, graph databases are well-suited for solving problems where relationships between data are crucial. For example, they’re used in fraud detection and analysis, product recommendation systems, modelling social networks, analytics and artificial intelligence, financial services, supply chain management, and knowledge bases.
Neo4j consists of several fundamental elements that allow for the creation of graph data models. The first element is nodes, which represent objects or data entities. Each node can have properties that contain information about it.
The next element is relationships, which connect nodes to each other and describe the dependencies between them. Relationships can also have their own properties. Node labelling allows for grouping nodes with similar characteristics, making it easier to search and analyze them. A single node can have multiple labels.
Neo4j utilizes a query language called Cypher, specifically designed to work with data stored as a graph. It’s a declarative language that allows for easy definitions of patterns and relationships. The language enables us to execute more complex queries, such as searching for paths between nodes, calculating relationship weights, or filtering results based on logical conditions.
Thanks to the creators of Neo4j, we can easily test how the database and Cypher work. We can choose to use the locally installed solution or the cloud-based application – Aura DB. Moreover, each of these options allows us to use a predefined set of sample data (playground).
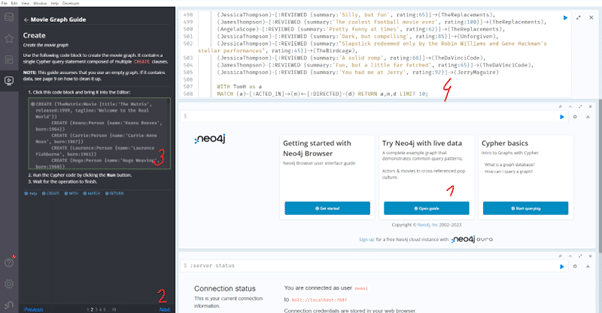
For the purpose of this article, I am using the Neo4j Desktop application, but you can also use Aura DB or download a Docker image. After launching, you will see the Bloom application interface (a tool for visualizing data) along with the “Try Neo4j with live data” message – click the “Open guide” button (1) to open the tutorial and go to the second page (2), where you will find a query that can be copied to the command line by clicking (3). All that’s left is to execute it (4). Below is an illustration of how to do it.
1. After launching, our data is ready for exploration. Let’s assume that we are fans of Keanu Reeves.
Let’s check if such an actor exists in our database:
MATCH (actor {name: “Keanu Reeves”}) RETURN actor
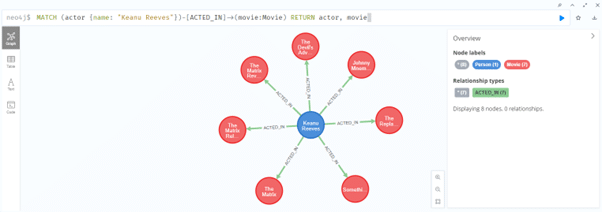
2. We will display all the movies in which he has acted:
MATCH (actor {name: “Keanu Reeves”})-[ACTED_IN]->(movie:Movie) RETURN actor, movie
3. And now all the actors who have acted with Keanu in any movie:
MATCH (keanu:Person {name:”Keanu Reeves”})-[:ACTED_IN]->(:Movie)<-[:ACTED_IN]-(coActors:Person) RETURN cofactors

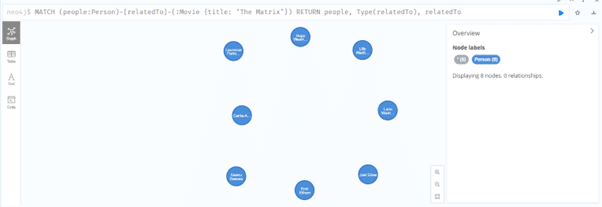
4. We can narrow down the results to the movie “The Matrix”:
MATCH (people:Person)-[relatedTo]-(:Movie {title: “The Matrix”}) RETURN people, Type(relatedTo), relatedTo
5. Finally, let’s find the shortest path between Keanu Reeves and Tom Hanks:
MATCH p=shortestPath( (keanu:Person {name:”Keanu Reeves”})-[*..10]-(tom:Person {name:”Tom Hanks”}) )
RETURN p
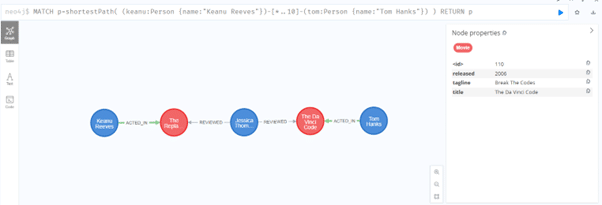
As you can see, the Cypher language seems intuitive – even though you’re not familiar with the exact syntax, you can guess what the query should return. Similarly, data visualization is much more intuitive and understandable in the form of a graph than in a tabular form.
A crucial aspect of creating a new Neo4j database is proper data modelling. To construct an effective model, it’s valuable to start by identifying the questions that the system needs to answer. In fact, this is a recommended approach by Neo4j.
Once the questions are identified, the graph structure should be designed to enable efficient and precise retrieval of answers to these questions. This often requires an iterative approach, where we gradually refine the model based on our needs.
Here are a few interesting examples of Neo4j’s practical applications in various projects:
In the era of the growing popularity of artificial intelligence, social networks, and massive datasets with increasing numbers of connections, it’s impossible to ignore the growing importance of graph databases. They offer an innovative way to organize and analyze information, enabling the discovery of deeper relationships and patterns.
Graph databases represent a promising technology that has the potential to revolutionize the way we organize, analyze, and utilize data. Their ability to model complex relationships between data and their efficiency in processing vast amounts of information make them invaluable tools in today’s data-driven world. Therefore, it’s worth keeping track of the development of this technology and understanding how it can impact our lives, not only professionally.
Get help with your CV and profile and be found for rewarding projects.
Register your profile