
In this article, software developer & emagineer explores the possibilities of building an application prototype with ChatGPT. In a step-by-step guide, he takes us through the process of building an app leveraging ChatGPT, showcasing the benefits and challenges of today’s AI solutions.
Many web developers at various stages of their careers create various ‘drawer’ projects – sometimes for educational purposes, other times to build a specific application.
Unfortunately, it seems very challenging to divide one’s time between professional work and projects we work on ‘for ourselves’, often only after working hours. Because of this, many such projects never see the light of day or are not developed to the extent they were intended.
However, for some time now we’ve had a tool that can overcome the initial difficulties in building a project prototype. That tool is AI, which – in the right hands – can become a very useful tool for developers.
My specialization is mainly in front-end and Angular, but I also have some experience in backend applications. I won’t try to build something using tools I’m not familiar with, so I choose typescript / nestjs / neo4j / graphql / angular as the technological stack.

Technology
The entire project will be set up as a monorepo using nx. I will use queries in the English language (although GPT has no problem with the Polish language).
I will try not to write my own code and rely solely on GPT – I will do it only if necessary to continue. I will use GPT 4 (ChatGPT July 20 Version) and the Code GPT plugin for Webstorm IDE.
Finally, I will skip tests or adhering to SOLID/KISS/DRY, and similar principles, following the two rules below:
The next challenge is choosing the application itself. Because we are trying to build something resembling a real application, we will create a knowledge base of supplements, their ingredients, interactions, and how they relate to each other. The application should:
In the right hands, AI can be a very useful tool for developers.
We want to find out what the latest versions of our libraries/frameworks are that are indexed by GPT.
I need applications/frameworks/libraries version numbers you’re aware of: nx, angular, nodejs, typescript, nestjs, neo4j.
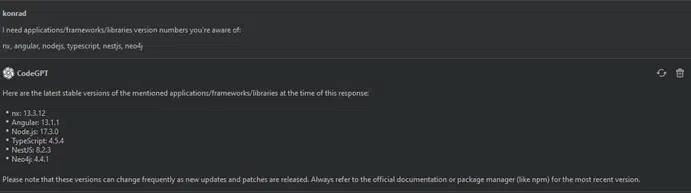
Since the publication of the above versions, many things have changed, so we need to keep that in mind:
How to start an Nx monorepo with multiple applications, using the Angular preset? I only need CLI commands for creation.
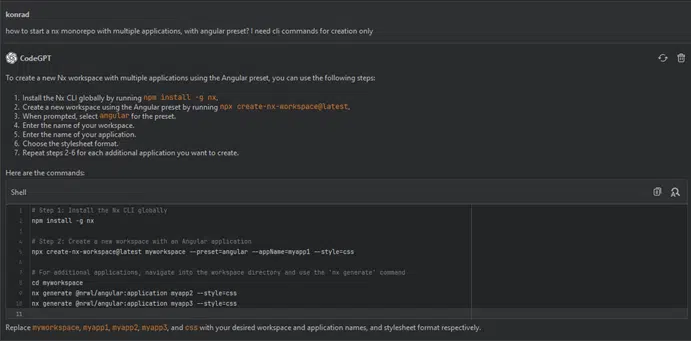
The last step is redundant; however, we can create the project using the following command (a slightly modified version):
npx create-nx-workspace@latest ai-suple –preset=angular –style=scss –appName=app
And we choose the options as follows:
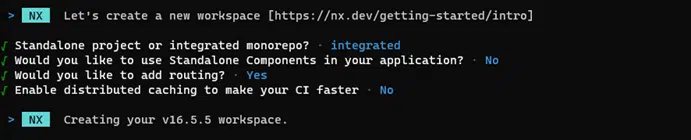
Now we want to add a backend application.
How to install and add a NestJS application named ‘api’ to an existing Nx monorepo?
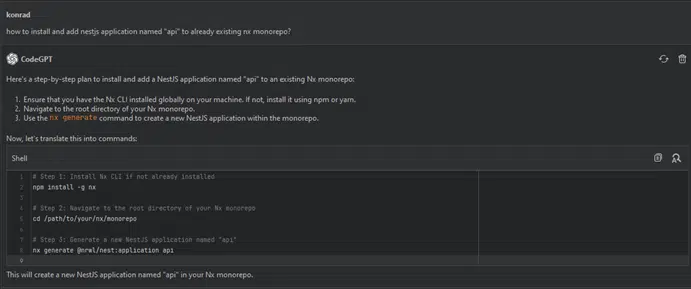
I run the above commands, everything works. The last element of the structure is the database. Here we have three options:
Each is fine, I will be using Neo4j Desktop, but often we also have Docker. We will need a script in the package.json to start the database.
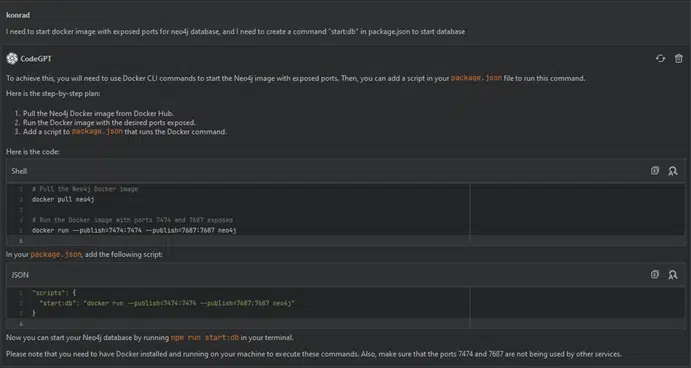
I need to start a Docker image with exposed ports for the Neo4j database, and I need to create a ‘start:db’ command in package.json to start the database.
Now, I want to start our project with a single command.
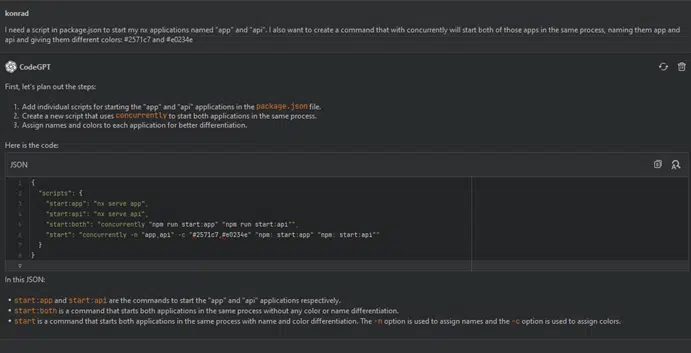
I need a script in package.json to start my Nx applications named ‘app’ and ‘api.’ I also want to create a command that, with ‘concurrently,’ will start both of those apps in the same process, naming them ‘app’ and ‘api,’ and giving them different colors: #2571c7 and #e0234e.
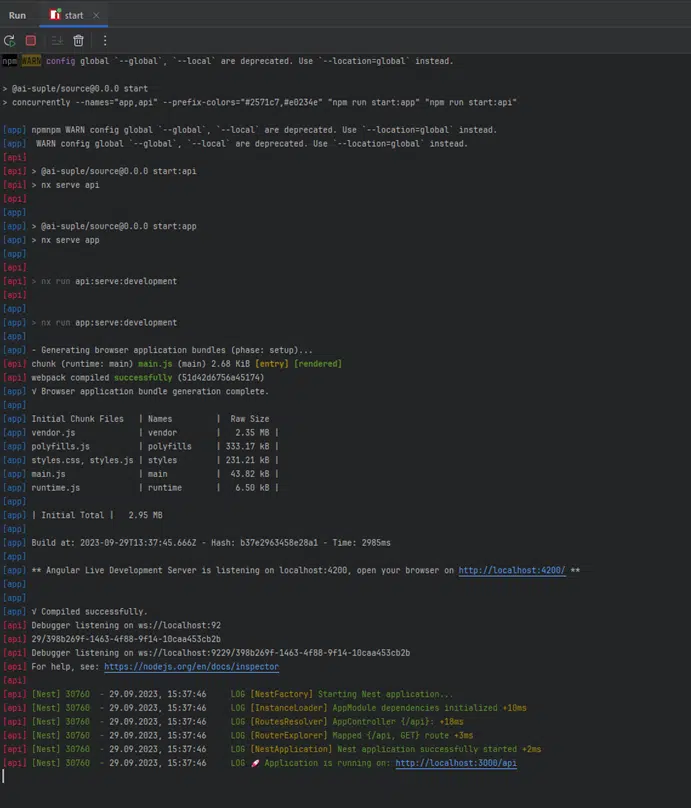
I’m installing ‘concurrently,’ making some script modifications (changing ‘start:both’ to ‘start’), and then running it – everything’s fine. The applications are running on ports 4200 and 3000.
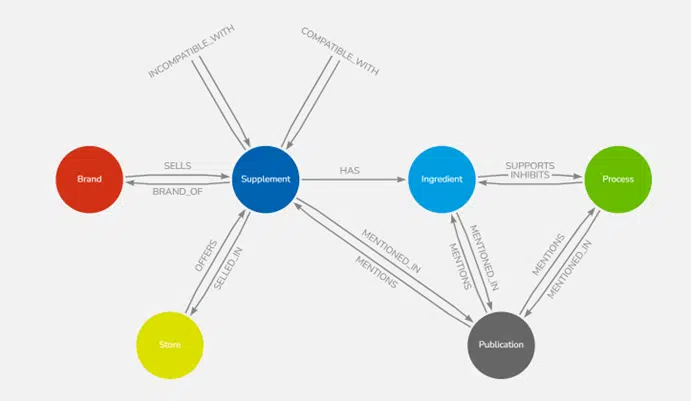
Now that all components of our system are working, we can proceed to build our model. If you want to learn more about Neo4j, I encourage you to check out the article Neo4j is revolutionising information management, linked above.
Using arrows.app, I’ve created a data model for Neo4j. Visualization of dependencies will help you better understand this model. It’s worth noting the clarity of the model – relationships between individual nodes are visible at first glance, which cannot be said for relational databases.
Propose a data model for @neo4j/graphql of the supplements, where:
The generated model looks good; we will add the necessary fields to it in the later part. Now we need to add this model to our backend application in the Nx monorepo. The application is called ‘api,’ and we’ll add it as a Nest library located in ‘libs/api/…’
GPT encountered challenges - several attempts at generating a GraphQL module have failed.
Unfortunately, several attempts to generate a correctly working GraphQL module have failed. GPT encountered a significant challenge and couldn’t provide a working configuration despite many attempts and query changes. So, I used the configuration I created for this article.
The model was generated for an older version of @neo4j/graphql, so we need to make a few changes to make everything work correctly:
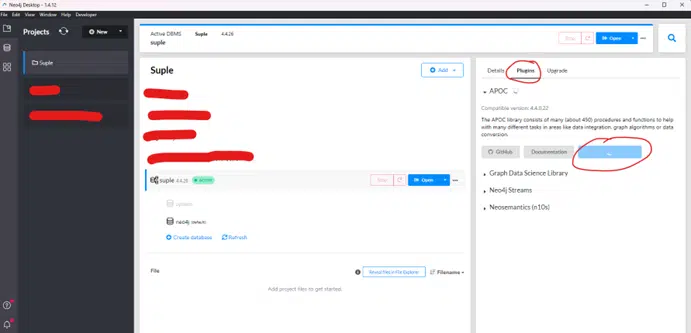
After this, our module works correctly. We check our model in the toolbox application, and here is the result:
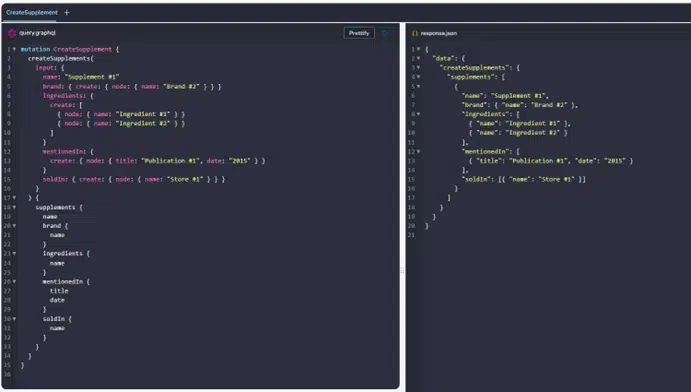
I created this query in toolbox with the help of syntax autocomplete. Let’s see if GPT can handle such a task:
having the @neo4j/graphql model defined as below, create a GraphQL mutation that will create a supplement with: name, brand, 2 ingredients, publication, and store.
The database is empty, so all nodes need to be created.
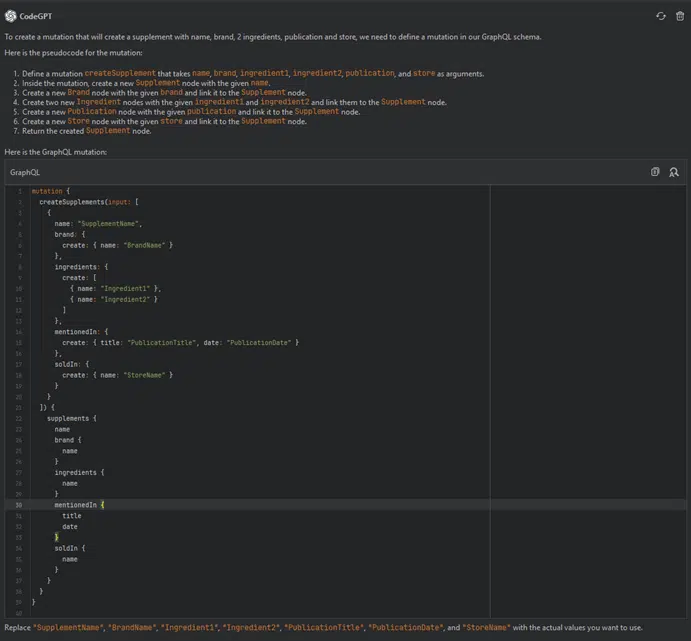
When we look at the previous example, we can notice that this time the mutation is not correct, but we are checking it in the toolbox.
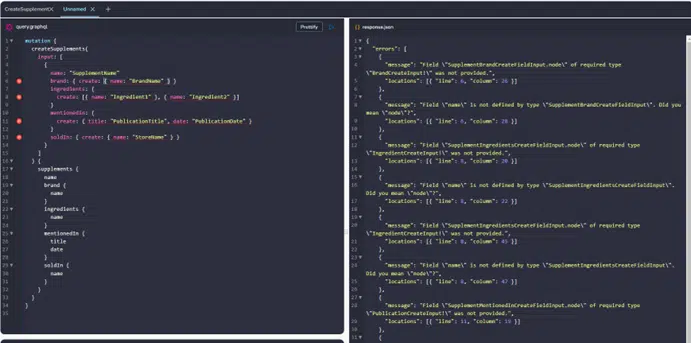
Let me suggest a correction:
wrap all create content in {node}, so it will look like: {create: {node: {…} }
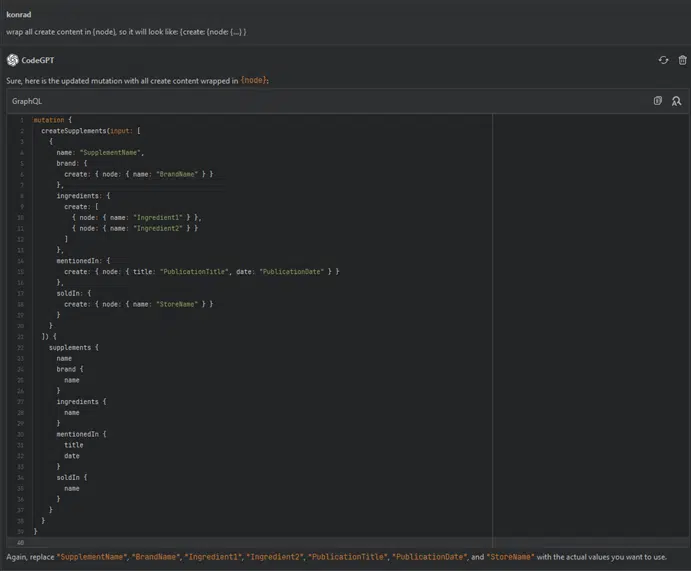
Now everything looks fine.
I was able to test the capabilities of GPT in the context of building a web application. It seems that AI is a useful tool that can significantly speed up the process of creating a prototype application.
However, not everything went smoothly – I encountered issues that required manual intervention. I haven’t addressed the topic of authorization yet (I’ll leave that for integration with the front-end), but GPT certainly has outdated data, and the generated model will be incorrect – I’ve checked.
To ensure the answers are as accurate and complete as possible, I asked some questions multiple times to clarify details – it didn’t take much time, but it’s worth mentioning from a research standpoint. A critical perspective proved to be crucial when leveraging GPT.
Nevertheless, I was able to achieve the intended goal. That’s all for the first part of the article. In the second part, we will focus on building the interface for the web application, which will be added to the existing application.
We need to be mindful of GPT's outdated data, which leads to incorrectly generated models.
Konrad Kaliciński
software developer, Wroclav
